[機器學習專案] Kaggle競賽-鐵達尼號生存預測(Top 3%)

若有轉載,請標明文章出處
這篇文章主要是一篇記錄和教學的綜合體,在我3個月前試圖想要從這個比賽入門,發現中文的文章比較少有到達Top5%的(或許現在有了!),最近完成成果之後,決定寫下來給有興趣加入資料科學以及機器學習的網友們參考。
此外,這篇文章會提及一些機器學習的演算法及基本觀念,我會盡量用很直觀的方式帶過,如果有興趣走這一塊的朋友,大神林軒田老師的機器學習基石及機器學習技法非常值得花時間學,從我碩士畢業到現在我大概花了6個多月,就把他當在學校上課一樣step by step的走,基礎會比較穩固,okay那我們開始吧。
比賽連結
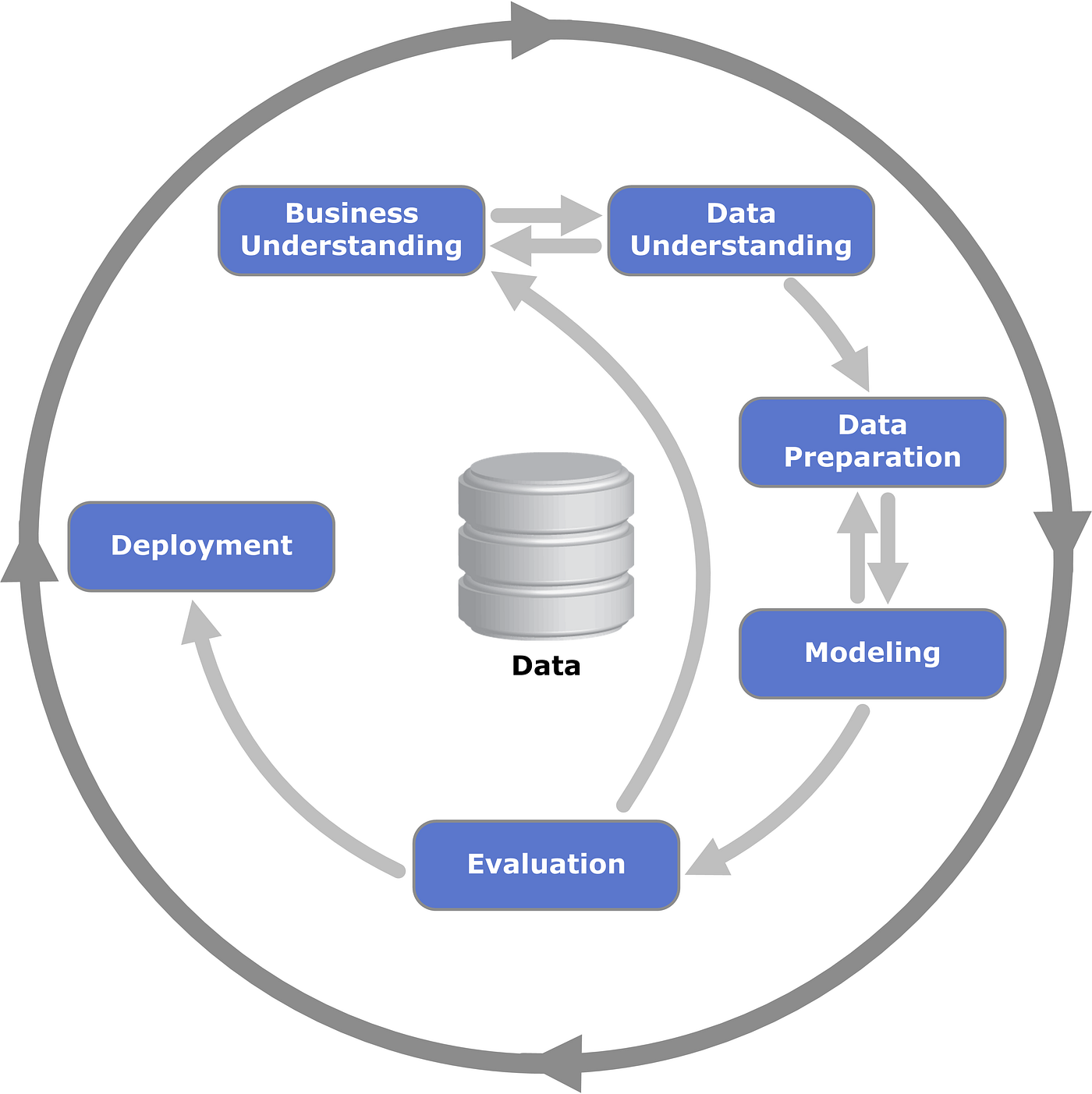
By Kenneth Jensen — Own work based on: ftp://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/18.0/en/ModelerCRISPDM.pdf (Figure 1), CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=24930610
上圖是一個跨產業資料採礦標準作業程序CRISP-DM,由於在Kaggle上我們並不會觸碰到業務面,所以我們可以從Data-Understanding這裡來切入,基本上一個專案會經過非常多次的探索性分析(EDA),然後取出多個特徵,可能是原本的特徵,或是經過調整的在模型上測試,本篇文章最後用5個特徵(性別、艙等、票價、是否成年、連結)來達到Top3%的公開排名(301/11455)。
第一次探索性分析(First EDA)
如同前言所提到的,這篇文章主要放在特徵工程及模型表現上,因此這邊列出幾個我自己做專案時也常常翻出來看的EDA:
中文:
[資料分析&機器學習] 第4.1講 : Kaggle競賽-鐵達尼號生存預測 (前16%排名) by Yeh James
分分钟,杀入Kaggle TOP 5% 系列(1)by 周知瑞
英文:
Titanic Data Science Solutions by Manav Sehgal
Base Model
在我們開始測試各式各樣的特徵之前,我們必須先選一個模型,當然我們盡量選用對抗噪聲較強的模型(SVM,KNN,隨機森林),基本上我的考量是這樣的:
(1) 廣泛性
鐵達尼號的資料集非常小僅有891筆資料,因此SVM及KNN較為人詬病的問題"在較大的資料集非常沒有效率"也會因為資料集小獲得紓解,然而,隨機森林由於其平行化計算的特質在資料集小或是大時的運算效能都不錯。因此在廣泛性上隨機森林得一分。
(2) 預處理
資料在餵進模型之前必須先經過預處理過程,SVM及KNN是以距離為基本來做超平面切分/鄰近投票,其中的手續比較多,也增加處理不好的風險,另一方面,隨機森林是以不純度函數來切分樣本,因此不需要歸一化或標準化,簡化了建模時的步驟。
如果是想要使用KNN及SVM的朋友,目前最大眾使用的是StandardScaler(扣掉平均值後除以標準差)以及MinMaxScaler(除以最大最小值),在Kaggle上的討論區上有人測試過兩種,基本上是case by case,可能兩者都試試看,來看哪個可以有比較好的LB Score,不過如果要比較優劣的話:
StandardScaler
- 好處 : 處理完之後皆符合常態分佈(平均值=0,標準差=1),這對大部分的演算法都是好的
- 壞處 : 如果你的特徵原本是很多0少數1的那種(sparse),經過處理之後就不sparse了,一旦資料量一大,運算較快的優勢就會消失
MinMaxScaler
- 好處 : 如同上所說,可以保持特徵的sparsity同時控制每個特徵維持相等的權重
- 壞處 : 由於處理完之後並沒有變換分佈,必須謹慎地確認演算法是否會因為資料分佈非高斯就表現得很差
若有朋友是用距離為基本度量的演算法有遇到問題的話,可以留言或是寄信討論,這邊我們使用隨機森林來做為特徵的測試環境
使用Jupyter Notebook匯入資料,合併訓練集和測試集,方便資料探索及特徵工程
首先我們設定一個最基本的模型,如果之後加入的特徵在準確率表現上比這個差,就可以判定該特徵含有太多噪聲,或是和生存與否關係不大,在鐵達尼號的資料集裡,我們從兩個特徵開始:
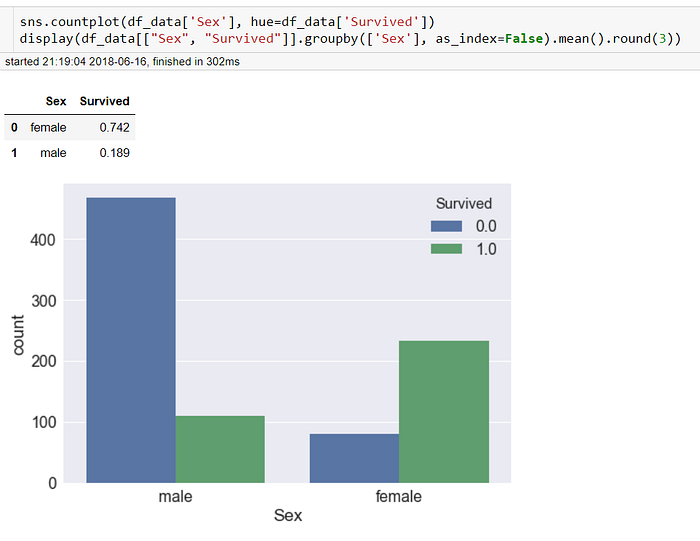
(1) 性別 : 在鐵達尼號中,大部分的男性都掛了(僅剩18%存活),而女性則大部分都存活了下來(~75%)
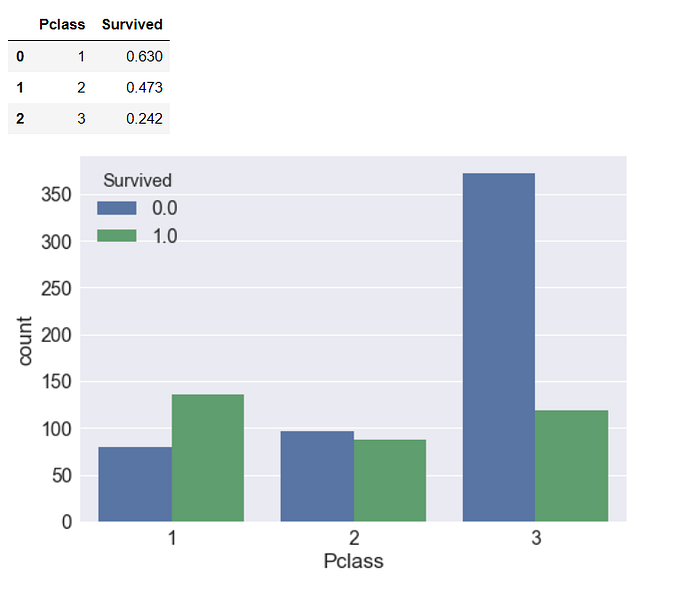
(2) 艙等 : 我們可以預期到,頭等艙的乘客生存機率會比較高,不論是逃生設備,或是沈船訊息可能最先傳到頭等艙,鐵達尼號有3個艙等 : 1,2,3 (姑且稱為頭等艙、商務艙和經濟艙XD?)
將性別資料轉換為 0, 1,0為女性,1為男性

把訓練集和測試集分開

將生還與否設定為目標(Y),其餘為訓練資料(X)

訓練隨機森林模型,利用Out-Of-Bag的data做為驗證資料集
- Out-Of-Bag做為驗證資料集 : 隨機森林演算法是由一群決策樹組成,單顆決策樹並不會用所有的訓練資料,每一次選一塊資料來訓練一顆決策樹時,剩下的資料並沒有被拿來訓練該顆決策樹,因此可以做為驗證資料,即Out-Of-Bag。
超參數調整
- 這篇文章的分析主要著重在特徵工程上,因此這裡並沒有選用最佳化的參數來訓練模型,其中有幾個選項,分別是max_depth, min_samples_split, min_samples_leaf......etc,其實都是為了防止overfitting,這裡我們簡單地選用min_samples_split=20。

我們在oob資料上獲得0.731的準確率,將結果提交到Kaggle上

我們在排行榜上獲得0.76555的準確率,這是一個基準值,如果你已經加入了很多特徵,但是準確率比0.76555低,表示你加入了太多噪聲很大的特徵,或是你的模型參數已經調過頭導致了overfitting,此時該做的就是回到最簡單的Base Model,一項一項特徵慢慢地加入。
票價(Fare)
票價和艙等都是屬於彰顯乘客社會地位的一個特徵,同時也可以在EDA當中發現,買票價格較高的乘客,他們的生存機率也較高。
由於票價分布非常廣及傾斜,有非常高的票價也有非常低的,我們將票價取log來畫圖會好看一點。(註 : 取log之後同時也可以解決傾斜的問題,若是在Regression Problem中也是必要的預處理)

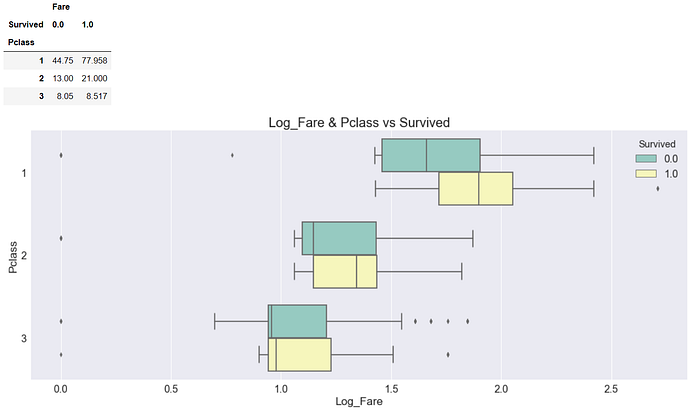
從表以及圖中我們都可以看出存活下來的乘客確實平均而言付出較高的票價,我們決定測試這個特徵,然而,測試之前,我們需要將票價切分成幾個區間,才不會讓模型overfit的太嚴重,如此問題就來了,切成幾塊比較合適呢?
首先填補缺失值,由於只有一項,我們填入中位數

我們用極限的觀點來考慮區間切分問題 :
- 當切分的區間太少時,區間內的資料太多一起平均,這樣沒有辦法看出差異性,使得特徵失真
- 當切分區間太多時,一點點票價的不同,都影響了生存率的高低,如此一來很明顯地會overfitting,並且,切分區間趨近於無限大時,就回到了原本的數值特徵
下列程式碼將票價分別切分成4,5,6的區間,並命名為新的特徵

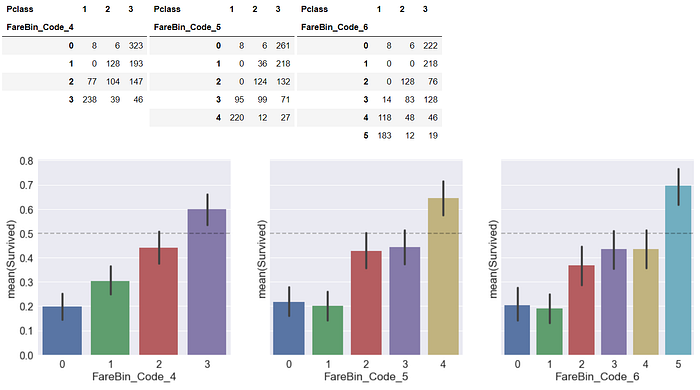
這裡有兩件值得提的事
- Pandas中提供了蠻多種切分數值特徵的方式,這裡選用qcut,qcut是以累積百分比來切分的,例如將副指令=4,就會以0%~25%, 25%~50%, 50%~75%, 75%~100% 來切分資料,好處是我們可以避免某個區間內的資料過少(skew problem)。
- 圖中虛線表示為機器隨機亂猜,應該要有50%的準確率,如果我們的特徵工程沒辦法將各區間分離開50%,那就沒什麼意義。
切分訓練集及測試集,將生還與否設為目標(Y),其餘為訓練資料(X),並顯示目前有的特徵

對於這樣一個特徵選擇(Feature Slection)的問題,這裡我們利用前向選擇法(RFE)做特徵選擇,關於特徵選擇的方法我們有幾個選項,一是用單變數的Chi square、或是information gain,但RFE可以考慮到特徵之間的交互作用,缺點是需要較大的運算資源,這點由於我們的資料集比較少而可以獲得緩解,在Sklearn上的實作也蠻簡單的
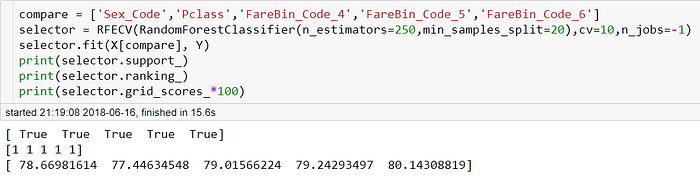
在CV上我們可以看到切分成6份可以得到比較高的CV分數,但是還沒有考慮到模型的random_state以及Cross-Validation切分的方式,我們必須小心謹慎的確認切成6份是否真的是最好的,下面針對CV及模型的random_state進行實驗,這段程式會稍微花一點時間,我的i5筆電花了2分36秒

作圖

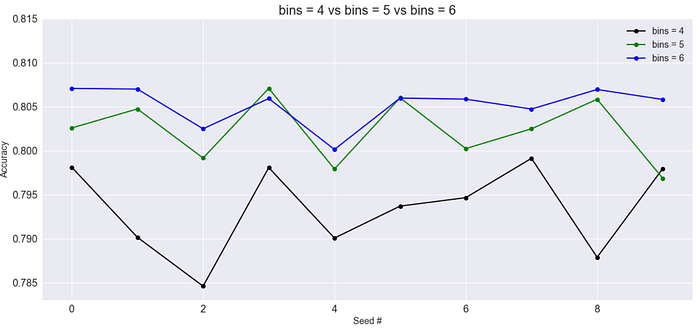
由上圖我們可以看出切分成4份的準確率較低,6份比5份稍微好一點,在CV在的結果是這樣,接下來我們分別將其提交到Kaggle上,這段程式碼和上面Base Model差不多,所以這裡就不再重複一次,我們直接顯示oob分數以及提交的結果
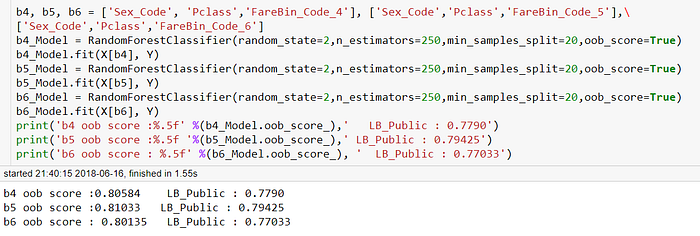
這裡我們可以看到,在排行榜上的分數反而是切分成5份最高分,而不是6份,這個情況在Titanic這個資料集上很常見,我認為是某種過度的特徵工程所帶來的overfitting,畢竟特徵工程在數學上也可以想像成原始特徵的非線性轉換,僅僅是我們賦予了每一種特徵工程對應的意義,然後相信這樣做是有用的,最終都必須得在CV以及排行榜上測試(P.S.這段僅僅是依照我的經驗來寫,如果有什麼理論依據,或是更好的解釋方式,歡迎一起討論!)
將b5_Model提交至Kaggle


我們可以得到0.79425的準確率,事實上,在Kaggle上這已經是Top22%的排名了,這也顯示出,多數的Kaggler在鐵達尼號這個比賽中都用了許多噪聲(noise)強或是互相冗餘(redundant)的特徵。
連結(Connected_Survival)
這個特徵相當有意思,主要是發現了乘客持有相同的船票意味著他們可能是家人或是朋友,而在訓練集上這些互相有連結的人常常是一起活下來或是一起喪命,我們從票根的特徵Ticket開始看起
在891個票根資訊中,獨立的有681項,這表示一定有乘客是持有相同的票根,這意味著他們可能一起分享某一區的座位......
建立家庭人數特徵(將兄弟姊妹數SibSp+父母小孩數Parch+1)方便接下來的觀察

建立持有相同票根的DataFrame,並顯示姓名、票價、艙位、家庭人數

觀察表格,從編號7,24,374,567,389這個群組來看,該家族有可能是全部一起喪命的(縱使有一個是測試集中的資料),也可以從姓名中看出,5名成員皆為Palsson家族,一位先生(Mr.)及兩位小姐(Miss)帶著兩位小男孩(Master)搭上了鐵達尼號,票根皆為349909,甚至票價也是同樣的,接著再看到編號8,172,869群組,皆為Johnson家族的成員,兩位女性(Mrs.及Miss)帶著一位小男孩(Master)搭上了船,這則是一個三位乘客皆存活的例子,也未必所有的群組都是同生同死(例如編號3,137),最後,我們可以從編號6,146的這個群組看出兩位一起搭船,但並非是親屬關係(姓名中的姓氏不同),因此可以推定可能是朋友或是基於甚麼原因共同搭船的人,同樣也有可能再傳難發生時互相幫忙
我們也可以透過家庭成員人數這個特徵來分類,Family_size = 1 但是又在群組內的,即非親屬關係,我們歸類為朋友,Family_size > 1則為家人
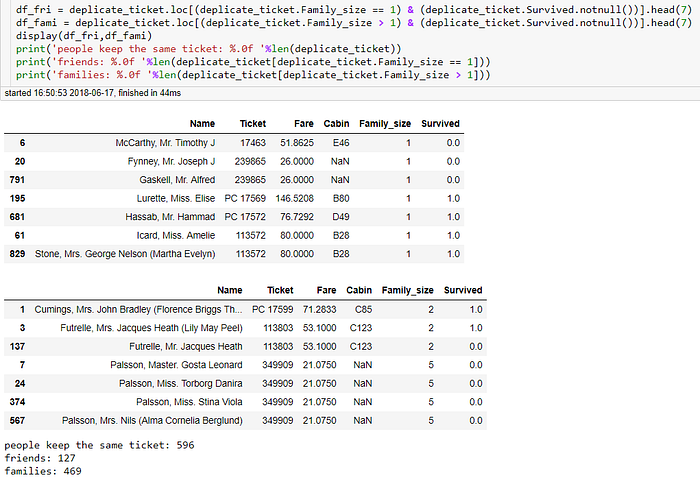
有約莫600位乘客和他人持有相同票根,其中大概有75%為家庭出遊。接著依照以觀察來創建一個新的特徵,這個部分感謝網友 @孫茂勛 參與討論,指出原本解釋不妥的部分,這讓我們的分析更加完整以及更容易閱讀,以下我們進入特徵工程的細節:
我們希望上表中票根 PC 17599 中的乘客建立Connected_Survival = 1,以及票根 17463 349909 中的乘客建立Connected_Survival = 0,但還須要多考慮沒有生還資訊的乘客(同個票根中Survived都是NaN 在測試集中)的乘客,將Connected_Survival = 0.5
- 過濾出重複的票根 :
if( len(df_grp) > 1) - 如果群組中有人生還 則定義 Connected_Survival = 1 :
if(smax == 1.0): - 沒有人生還,則定義Connected_Survival = 0 :
if( smin == 0.0): - 剩下的沒有生還資訊,定義Connected_Survival = 0.5 : 程式碼第一行
df_data['Connected_Survival'] = 0.5
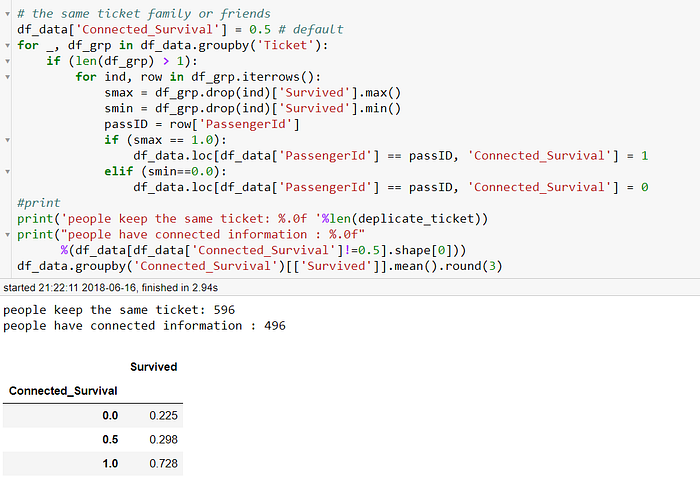
我們得到在596位持有彼此持有相同票根的乘客,其中496位含有連結關係(0 or 1 ),將其分組分別計算生還率,也還能把資料分的蠻開的,其中連結=1的生存率更是從0.298直接飆升至0.728
完成特徵工程,分離訓練集、測試集,並分離出生還與否(Y)以及訓練資料(X)

加入模型、訓練、觀察oob score

oob score來到了0.820,將預測提交至Kaggle觀看結果


我們從0.79425來到了0.80382,這表示我們加入了一個相當有效果的特徵!
年齡(Age)
在這個特徵中我們會面臨20%缺失值的問題,和前面的票價(Fare)僅僅只有一項缺失值相比,缺的不少,而這很有可能影響預測,首先我們分兩個部分來討論:
截止目前為止,使用性別及艙等可以達到0.76555的準確率,後來加入了2項特徵則約莫提升了4%,因此如果缺失年齡特別都屬於某個性別,或是特別都屬於某個艙等,就很有可能影響預測,以下觀察缺失值分佈的情況

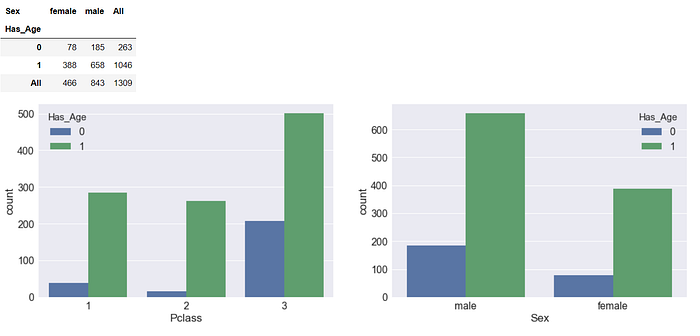
從左圖我們可以明顯的看出年齡缺失值蠻大部分在3等艙,如果年齡真的是個重要特徵,則我們對3等艙的觀察就會失真,保守的作法是觀察1,2艙等中年齡對存活與否的影響。
右圖則顯示了缺失值對性別的分布,搭配著表格看的話,466位女性有78位缺失年齡(16.7%),843位男性有185位缺失年齡(21.9%),比例差了5%,男性缺失年齡稍微多一點,如果年齡對生存與否有影響的話,可能可以搭配男性藉此被區分出更多的生還者(例如男性小孩生還率有可能高於男性成人)
1,2艙之中,年齡對存活與否的影響:

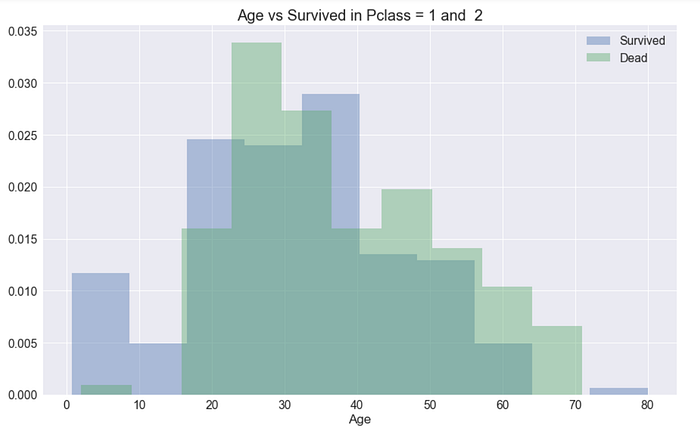
圖中我們可以看到,左邊藍色的部分多出了一塊,也就是這部分生存率較高的,約<16歲,表示青少年以下(包含小孩)會有較高的生存率,同時,其餘部分也顯示出了,若>16歲,基本上年齡不算是一個顯著的特徵來判定是否生還,而70~80歲的這個區間,由於樣本數太少,因此不列入採計。綜合上述3張圖的討論,我認為找出那些<16歲的缺失值是重要的,這會影響預測,而>16歲的部分則不採用,否則只是擬合了噪聲,因此年齡這個特徵可以抽取出<16歲及>16歲做為一個2元特徵
填入缺失值的方式我們選擇使用姓名當中的稱謂中位數來填補,比起填中位數要準確的多
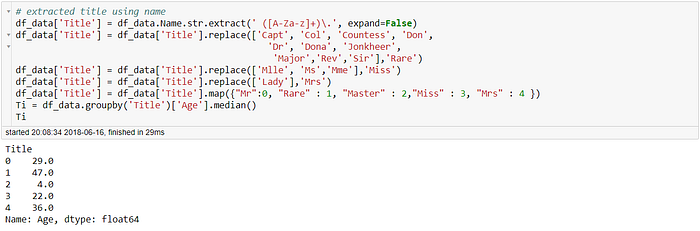
不動原始特徵Age,將填滿年齡的特徵創建為Ti_Age,分為<16歲及>16歲,命名為Ti_Minor

完成特徵工程,分離訓練集、測試集,分離出生還與否(Y)以及訓練資料(X)

加入模型、訓練、觀察oob score

得到了0.8417的oob score,也有可能是overfittng!,將結果提交至Kaggle


我們的分數來到了0.82296,已經達到11487個隊伍中的第301名(Top 3%)!
家庭人數(Family_size)
家庭人數這個特徵我最後並沒有加入模型,加入時雖然CV時升高,但提交到Kaggle時分數卻降低,雖然板上的前輩說要相信CV的分數,但我認為這個特徵是冗餘(redundant)的,雖然可以用correlation matrix來確認相關性,但實際上仍然有許多特徵之間的關係是非線性的,討論區上也發表了家庭人數可能是冗餘的相關言論,我們來看看
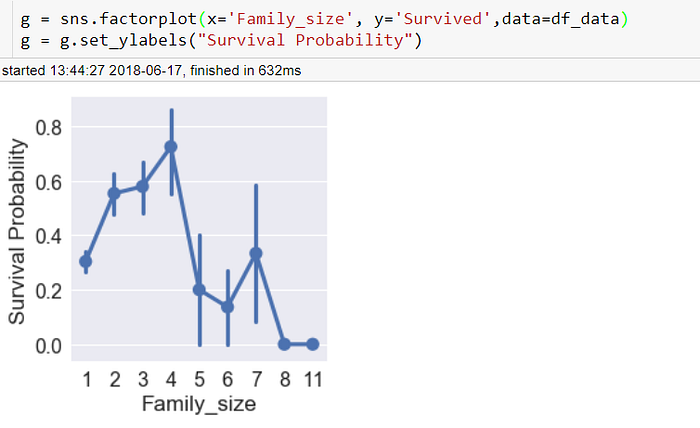
我們可以看到獨自一人的生存機率低,2~4人的家庭生還機率比較高,之後隨著人數增加而遞減,這時候我們就可能會腦補 : 獨自一人可能逃生時沒有受到幫助,所以生還率低,2~4人可以互相幫忙,但是人太多時可能又會因為無法找齊全部的家人逃生時有猶豫等等,而將其分成3類,獨自一人,2~4人,5人以上,分析如下
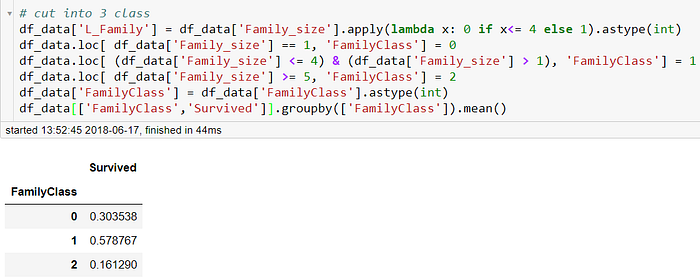
然而,這有可能只是我們的空想,我們來看看家庭人數對性別的分析圖形
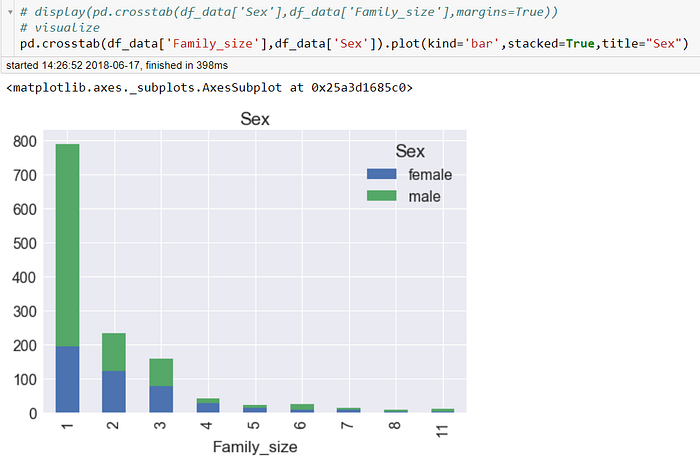
我們看家庭人數=1,真的是因為獨自一人沒有受到幫助而導致較低的生存率嗎? 有可能,但是不見得,上表中我們可以清楚看到家庭人數=1之中有接近將近75%的男性,男性的生存率本來就低,FamilyClass=0很有可能僅僅是性別特徵的一個重複而已!
然而家庭人數2~4呢? 是否真的是因為互相幫忙導致的生存率提高 還是又是其他特徵的投射而已? 我們來看家庭人數對小孩數量的分析
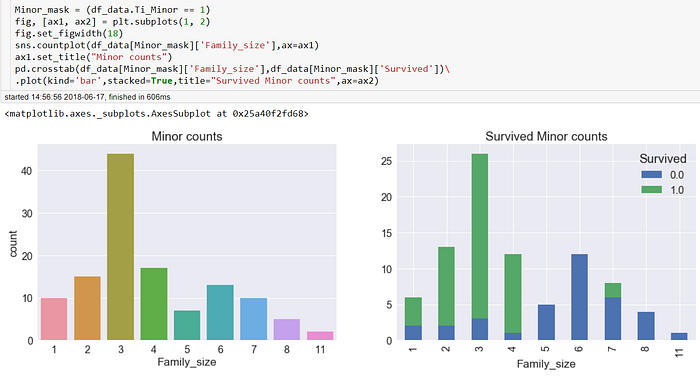
在家庭人數=2,3,4中,除了小孩的個數較高之外,存活的比例也非常高,這意味著家庭人數=2~4人的生存率較高很有可能僅僅是小孩存活的多,這已經涵蓋在Minor的特徵當中!
至於剩下的 Family_size >5人呢? 從分析中並沒有看出和其他特徵相關的影子,但如果我們僅是猜測其生還率低的原因是因為找不到其他家人猶豫而降低了生還率,這個理由我們在連結(Connected_Survival)已經做過同樣的推測,若僅是因為這個理由多造一個特徵,那確確實實又是冗餘了!
完整程式碼
後記
參與這項競賽的目的是為了瞭解一個機器學習建模的專案是怎麼樣進行的,的確,大部分的時間都花在特徵工程上,實際上調參數的時間很少甚至是不太需要調,其實真的很容易overfitting! 個人這次花在鐵達尼號的競賽上約3個月,大概每兩天研究一次6~10小時(當兵的休假也算是閒),鐵達尼號算是一個入門資源很豐富的項目,建議就算連英文不好都要帶著google翻譯直接殺進去看各式各樣的kernel,會很有收穫,同時我的Medium上也會繼續記錄各種我嘗試過Machine Learning的side project!
延伸閱讀
Pandas101 Numpy101 RegularExpression — 為資料清理、探索式分析、特徵工程、資料管線流、打下穩固基礎
資料很大,個人筆電handle不住怎麼辦? 在雲端上使用Jupyter notebook [part 1 ]

若你有任何問題,歡迎直接在下面留言,或是寄信到我的信箱yltsai0609@gmail.com ,我收到信之後會盡快回復給你!
Reference
Recursive Forward Elimination Workflow to 0.82296
